
While making conclusion in a hypothesis testing, there is always a possibility to occur errors – known as type I and type II errors. Since the test is based on probabilities, there is always a chance of making an incorrect conclusion.
- Type I error – We reject the null hypothesis when it is true. Then we commit a type I error. The probability of making the wrong decision when the null hypothesis is true is known as α (level of significance).
- Type II error – We accept the null hypothesis when it is false. Then we commit a type II error. The probability of accepting the null hypothesis when it is false is known as β.
Suppose in a cosmetic manufacturing industry, when the UV level of sun screen is at the appropriate level – they reject the lot (Type I error). And when the UV level of sun screen is not at the appropriate level – they accept the lot (Type II error).
Let us have a brief overview; in real life manufacturing or service processes, we first do sampling (to collect samples) because it is not always possible to do analysis on whole data (population). Suppose in a beverage manufacturing industry, they produce lakhs of bottle cans – it is time consuming to measure the quality dimensions of whole outputs and in such cases we apply sampling to collect samples. Here, we do not know the population standard deviation and hence we have to use t test.
The commonly used sample test methods are
- One sample t test – We use one sample t test when we have one sample group. By doing so, we would be able to find whether the mean is significantly different or not with regards to our target specification.
For e.g. in a pharmaceutical company, QA officer collects a samples of 10 tablets to measure the dissolution rate of a drug. Here, we can find whether the mean of a dissolution rate is significant to our target dissolution rate or not.
- Two sample t test – We use two sample t test when we have two independent sample groups. By doing so, we would be able to find whether the means are significantly different or not with regards to our target specification. And we would be able to compare which one is good.
For e.g. in a pharmaceutical company, QA officer collects a two sample groups (A and B) each of 10 tablets to measure the dissolution rate of a drug. We can compare which of these types have a better dissolution rate and hence we able to choose the best one.
By now we know the basic concepts of sample tests, when we have one sample we use one sample t – test and when we have two samples we use two sample t – test. In many scenarios, we will have more than two sample groups say three or four sample groups then “What can we do?” We can go for ANOVA test. Here, we can use more than two sample groups for analysis.
To discover the importance of t-tests and ANOVA, check our blogs
Suppose in a beverage manufacturing company, a quality inspector wants to know whether the bottle caps diameters are equal to 3 cm or not. If the bottle caps diameters are not equal to 3 cm then it won’t fit during the filling process.
(One sample t-test)
- The first step is to do sampling. We collected a sample of 50 bottles (n=50) and measured the diameters of all the bottles.
- Based on the measurement, we got mean (ȳ)=3.3 and standard deviation (s)=1.3
- Now state the hypotheses –
- Null hypothesis (H0) = the bottle diameter is equal to 3 cm.
- Alternative hypothesis (H1) = the bottle diameter is not equal to 3 cm.
- We set the level of significance (α) as 0.05 (5%).
- Compute the test statistic – we will apply t- statistic (since population standard deviation is unknown).
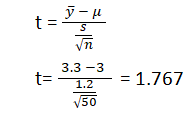
- Now say p value = 0.023 (based on test statistic)
- Making conclusion –
Since we know,
- p value < α, Reject Null Hypothesis
- p value > α, Accept Null Hypothesis
Here, p value < alpha value (i.e. 0.023 < 0.05) and hence we reject the null hypothesis. Therefore the bottle diameter is not equal to 3 cm.